Multimodal learning with latent space models has the potential to help learn deeper, more useful representations that help getting better performance, even in missing modality scenarios. In this project we leverage latent space based model to perform inference and reconstruction in all missing modality combinations. We trained a Multimodal Variational Auto Encoder which uses a product of Experts based inference network on three different modalities consisting of MNIST handwritten digit images in two languages and spoken digit recordings for our experiments. We trained the model in a subsampled training paradigm using an ELBO loss that comprised the modality reconstruction losses, label cross-entropy loss as well as the Kullback-Leibler divergence for the latent distribution. We evaluated the total ELBO loss , individual reconstruction losses, classification accuracy and visual reconstruction outputs as part of our analysis. We observed encouraging results both in terms of successful convergence as well as accurate reconstructions.
We approached the missing modality reconstruction and classification based problem using a Multimodal Variational Autoencoder(MVAE). Our model used a tree like graph where the different modalities define the observation nodes. It consists of parallel fully connected encoder and decoder networks associated with each modality as part of a VAE and a product of experts technique for late fusion of the respective latent distribution parameters from each encoder to get a final representation. An additional linear decoder branch was used for label classification.Each modality has its own inference network. This model was trained by optimizing an estimated lower bound (ELBO) on the marginal likelihood of observed data, i.e reconstructions of the modalities as well as the classification loss.
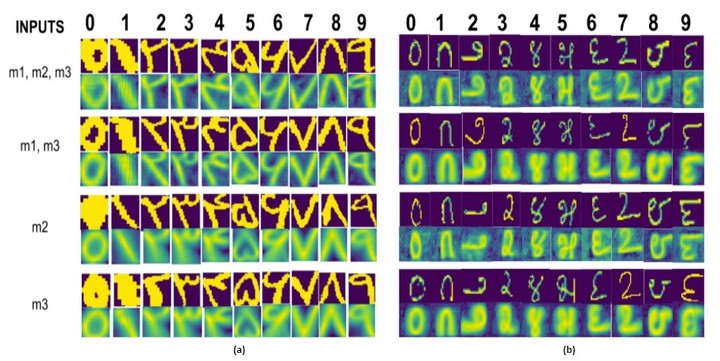
We also used a sampling based training scheme such that for each training example containing modalities, we obtained the loss for all combinations of modalities given to the model, this ensured the learned model generalized to perform well in reconstructing given any combination set of the modalities. We used three modalities for experimentation and trained the model on a MNIST dataset with images in two languages, Farsi and Kannada as first two modalities and speech utterances of the MNIST digits as the third modality.
The model performed well in terms of the convergence of ELBO loss, individual reconstruction losses, classification accuracy as well as the final visual reconstructions of the modalities. We also performed various analyses in terms of hyperparameter tuning, reconstruction under different modality combinations as well as analysis of disentanglement of representation property.