This project was done as part of my final project submission for COMP767: Reinforcement Learning course at McGill University
In the recent years, significant work has been done in the field of Deep Reinforcement Learning, to solve challenging problems in many diverse domains. One such example, are Policy gradient algorithms, which are ubiquitous in state-of-the-art continuous control tasks. Policy gradient methods can be generally divided into two groups: off-policy gradient methods, such as Deep Deterministic Policy Gradients (DDPG) , Twin Delayed Deep Deterministic (TD3) , Soft Actor Critic (SAC) and on-policy methods, such as Trust Region Policy Optimization (TRPO) .
However, despite these successes on paper, reproducing deep RL results is rarely straightforward. There are many sources of possible instability and variance including extrinsic factors (such as hyper-parameters, noise-functions used) or intrinsic factors (such as random seeds, environment properties).
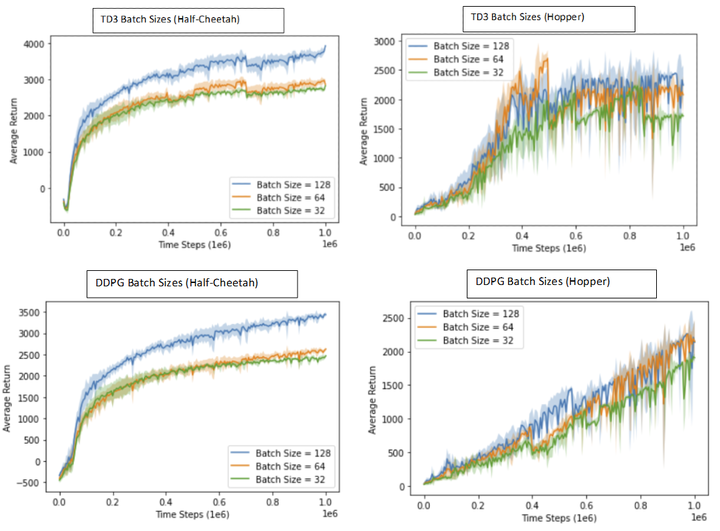
In this project, we perform two different analysis on these policy gradient methods: (i) Reproduction and Comparison: We implement a variant of DDPG, based on the original paper. We then attempt to reproduce the results of DDPG (our implementation) and TD3 and compare them with the well-established methods of REINFORCE and A2C. (ii) Hyper-Parameter Tuning: We also, study the effect of various Hyper-Parameters(namely Network Size, Batch Sizes) on the performance of these methods.